
Database transaction & ACID
데이터베이스는 서비스 개발에 있어 데이터를 저장/수정 하는데 필수적으로 쓰인다. 여기서 여러 작업들이 발생하는데,
여러 작업을 하나의 단위로 묶어 처리할 때 transaction을 사용한다.
이를 통해 작업이 모두 실행되거나 실행되지 않는 all or nothing 성격을 가지며, 데이터의 정합성을 보장한다.
예를 들어, 2명의 사용자가 하나의 계좌에서 입출금을 한다고 보자.
입금자와 출금자가 순서대로 만원씩 넣고 빼는 과정에서 입금이 출금보다 먼저 이루어지도록 보장하지 않으면 출금은 이루어질 수 없다.
transaction을 통해 계좌 뿐 아니라 정보의 순서 그리고 실행의 보장이 이루어지고,
데이터의 정합성과 유효성을 보장할 수 있다.
transaction의 특징인 ACID는 4개 성격을 가진다.
Atomicity(원자성)
transaction에서 처리된 작업은 부분적으로 실행되거나 중간에 중단하지 않도록 보장한다. 모든 작업이 성공적으로 반영되거나 반영되지 않도록 보장한다.
Consistency(일관성)
transaction이 성공적으로 완료되면 이가 반영된 데이터베이스 상태는 일관적으로 유지되어야한다. 예를 들어, 송금 과정에서 금액의 데이터 타입이 integer이면 모든 금액의 데이터는 정수형이어야 한다.
Isolation(독립성)
여러개의 transaction이 실행될 때 서로의 연산 작업이 끼어들지 않도록 보장한다. 이는 서로간 중간 데이터를 볼 수 없으며, 간섭할 수 없음을 뜻한다.
Durability(지속성)
transaction 이 성공적으로 수행된 결과는 영원히 반영되어야한다. 만약 데이터베이스가 문제가 발생해도 로그 등을 통해 장애 발생 이전으로 완료된 transaction을 복구할 수 있다.
Reference
ACID — Wikipedia
DB record Locking
데이터베이스에서 여러 요청을 transaction 단위로 처리한다고 했다.
앞서 설명한 ACID 속성을 위해선 데이터베이스 Lock이 필요하다.
Lock은 한 프로세스가 리소스에 접근하고 있을 때,
다른 프로세스가 함부로 수정하거나 삭제하지 못하도록 막는 역할과 동시에 transaction이 순차적으로 처리되도록 보장한다.
Lock 종류
- Shared Lock
- Exclusive Lock
Shared Lock
Shared(s) lock은 데이터를 읽을때 사용되는 lock이다.
각 s lock 은 서로간 동시에 접근이 가능하여 여러 사용자가 동시에 데이터를 읽을 수 있다.
하지만, s lock이 걸린 데이터에는 Exclusive(x) lock을 사용할 수 없다.
shared lock은 데이터 조회를 보장. 쓰고 삭제하는 x lock 배제
Exclusive Lock
Exclusive(x) lock은 데이터를 수정할 때 사용되는 lock이며, 해당 transaction이 완료(commit)될 때까지 유지된다.
x lock이 걸린 데이터는 다른 transaction에서 접근이 불가하고,
해당 lock은 다른 transaction이 수행되는 데이터에도 접근할 수 없다. 단어 뜻 그대로 배타적이다.
exclusive lock은 데이터 수정을 보장. 다른 lock과 배타적으로 실행. 서로간 간섭불가
Lock은 특정 데이터베이스, 테이블, 데이터에 대한 우선권을 가지기 위해 범위도 지정할 수 있다.
Lock 범위
- Database
- File
- Table
- Page&Block
- Column
- Row
Database
데이터베이스 범위의 lock은 가장 큰 단위이다. 하나의 session만이 DB 접그니 허용되고, 주로 DB 버전 업데이트 혹은 DB 전체 설정값을 수정할 때 쓰인다.
File
데이터베이스의 물리적인 파일에 lock을 설정한다. 이는 table, row 등 실제 데이터가 저장되는 저장소이며 잘 쓰이지 않는다.
Table
데이터베이스의 Table 단위에 lock을 설정한다. 이는 테이블의 행을 수정하거나 테이블에 영향을 주는 변경 작업 시 사용된다. DDL(Data Definition Language): CREATE, ALTER, DROP 구문 작업시 많이 쓰인다.
Page&Block
File의 세부단위인 page, block 단위로 lock을 설정하며, file과 같이 잘 쓰이지 않는 lock이다.
Column
Table의 column을 기준으로 lock을 설정한다. 하지만, Table 단위보다 lock 과정이 더 복잡하고 리소스가 많이 필요하여 Table lock을 더 많이 쓴다.
Row
Table 속 하나의 row 데이터를 기준으로 lock을 설정한다. DML(Data Manipulation Language): SELECT, INSERT, UPDATE, DELETE 구문 작업시 사용하며, 가장 일반적인 Lock이다.
Reference
MySQL :: MySQL 8.0 Reference Manual :: 15.7.1 InnoDB Locking
DB Transaction isolation level
Isolation은 ACID의 I로 DB에서 transaction이 처리될 때 서로간의 고립 정도를 정할 수 있다.
Isolation level이 낮으면 여러 사용자가 동일한 데이터를 동시에 접근할 수 있지만,
동시 접근으로 인한 Dirty read, Lost updates 와 같은 현상이 발생할 수 있다.
반대로 Isolation level 이 높을 경우, 이러한 현상은 줄어들지만 더 많은 리소스가 필요하고, transaction 간 blocking이 일어날 수 있다.
Isolation level
- READ UNCOMMITTED
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
Isolation level에 따른 동시성 현상은 Dirty read, Lost updates, Non-repeatable read, Phantom read 가 있다.
이는 각 단계를 2개의 transaction과 같이 설명하겠다.
READ UNCOMMITTED
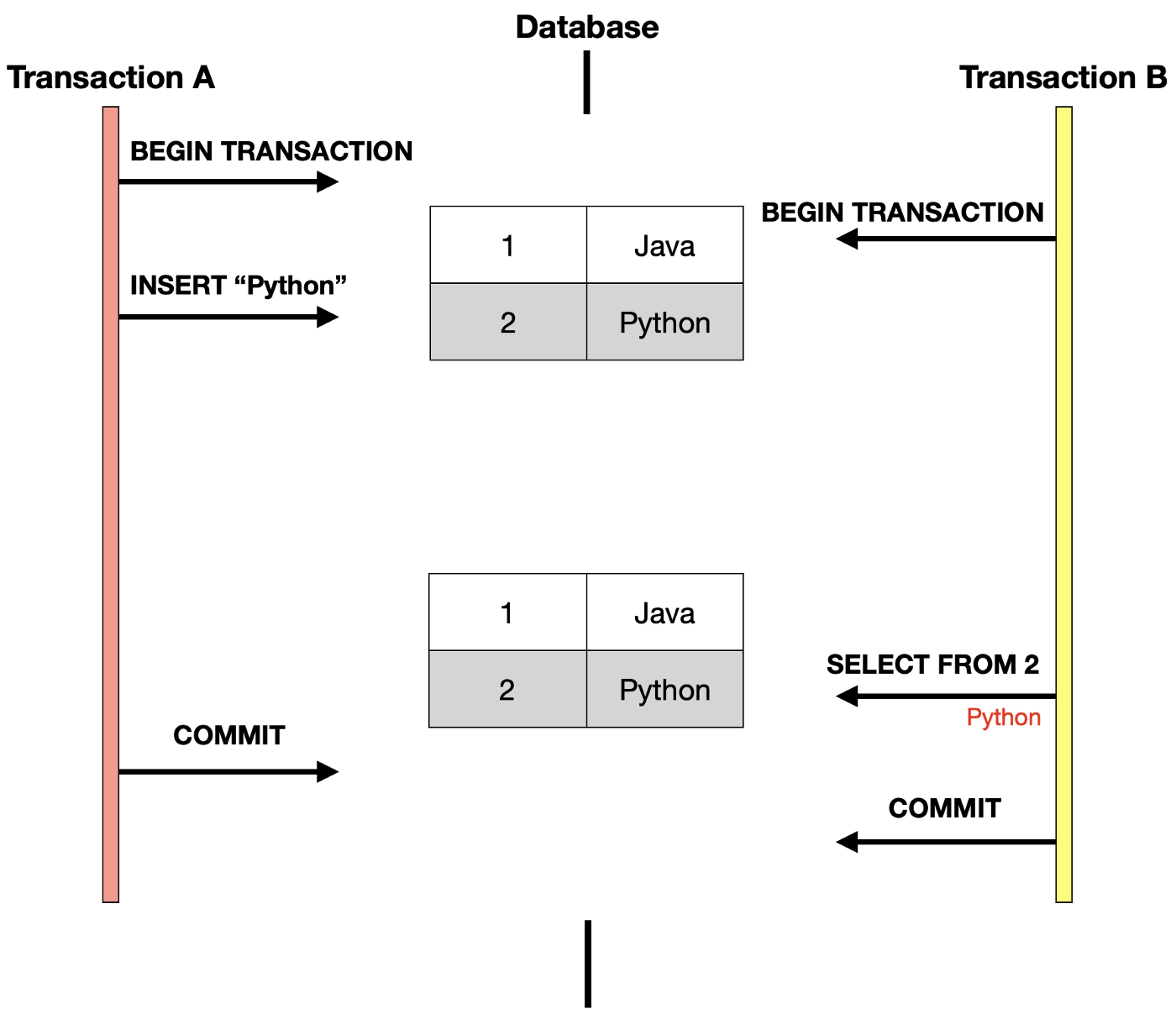
Read Uncommitted는 commit이 되지 않은 transaction의 변경점을 다른 transaction에서 읽을 수 있다.
transaction A에서 PK 2의 “Python” 데이터를 입력하고 commit 하기 전,
Transaction B에서 PK 2의 정보를 열람했을 때 값이 반환된다.
Read Uncommitted level에서는 SELECT query가 수행되는 동안 해당 데이터에 대한 Shared Lock이 걸리지 않고, 다른 transaction이 작업 중인 데이터 조회를 허용하게 된다.
이렇게 데이터의 일관성을 유지하지 못하게 되고, commit 되지 않은 정보를 볼 수 있는 현상을 Dirty Read라고 한다.
Dirty Read는 Read Uncommitted level에서 발생
READ COMMITTED

Read Uncommitted와 달리, commit이 된 변경점만 읽어올 수 있는 level이다.
transaction A에서 변경한 “Kotlin” 값을 commit 하기 전, transaction B에서 PK 2 데이터를 조회하면
UNDO 영역의백업된 데이터 “Python”을 읽어온다. transaction A에서 commit 이후에는 변경된 값 “Kotlin”을 조회한다.
Read Committed level에서 SELECT query가 실행되는 동안 Shared Lock이 작동한다.
이는 한 transaction이 실행되는 동안 다른 transaction은 해당 데이터를 조회만 가능한 상태를 뜻한다.
결국 A transaction에서 변경 후 적용된 결과를 B에서 수정은 불가하지만 조회는 가능하게 된다.
작업 중 조회하는 Dirty Read는 발생하지 않지만, 위 예제처럼 B가 A의 수정된 결과값 “Kotlin”을 읽어오게 되는 현상이 발생하고,
이처럼 다른 transaction으로 인해 일정하지 않은 결과값을 불러오는 현상을 Non-Repeatable Read라고 한다.
이는, transaction 간 isolation을 완전히 보장하지 못함을 뜻하고,
금융권/이커머스와 같이 각 transaction의 정확도가 중요한 웹 어플리케이션 구동에 적합하지 않은 설정이다.
대부분의 RDB에서 기본적으로 사용되는 Isolation level이지만, 완전한 데이터 정합성은 보장할 수 없다.
Non-Repeatable Read는 Read Committed level 이하에서 발생
REPEATABLE READ

commit이 적용된 모든 결과를 불러오는 Read Committed와 달리, Repeatable Read는 transaction이 시작되기 전 commit된 결과만 조회한다.
transaction B가 먼저 시작되고, transaction A에서 값을 수정 후 commit이 먼저 이루어졌다. 하지만, transaction B가 바라보는 관점은 시작 전 상태를 바라보기 때문에 A 에서 변경된 “Kotlin” 값이 아닌 기존 값 “Python”을 바라본다.
Repeatable Read level은 transaction이 완료되기 전까지 SELECT query가 사용되는 모든 데이터에 Shared Lock이 걸린다.
그러기에 각 transaction에서 조회한 데이터는 항상 동일하고 다른 transaction은 해당 데이터에 대해 수정이 불가하다.
수정이 이루어져도 해당 transaction이 시작되기 전데이터를 바라보기 때문에 일관적인 결과를 얻을 수 있다.
이렇게 각 transaction의 isolation을 보장하고, Non-Repeatable Read 를 배제할 수 있다.
Repeatable Read는 MySQL DBMS에서 기본 설정으로 쓰이고, 부정합이 발생하지 않지만,
transaction에 해당되는 데이터의 수정이 불가하고, Lock 범위가 넓어 성능이 안좋은 단점이 있다.
또한, UPDATE 부정합과 Phantom Read 같은 데이터 부정합이 생길 수 있다.
UPDATE 부정합
| CREATE TABLE User ( | |
| id INT PRIMARY KEY, | |
| name VARCHAR(100)); | |
| INSERT INTO User (id, name) VALUES (1, "no_name"); | |
| -- transaction A | |
| START TRANSACTION; | |
| SELECT * FROM User WHERE name="no_name"; | |
| -- transaction B | |
| START TRANSACTION; | |
| SELECT * FROM User WHERE name="no_name"; | |
| UPDATE User SET name="i_born" WHERE name="no_name"; | |
| COMMIT; | |
| -- commit transaction B | |
| SELECT * FROM User WHERE name="no_name"; | |
| UPDATE User SET name="i_die" WHERE name="no_name"; | |
| COMMIT; | |
| -- commit transaction A |
UPDATE 부정합 example (ref.link)
위 예제에서 transaction A는 “no_name"을 “i_born"으로 수정하는 쿼리이고, B는 “i_die"으로 수정하는 쿼리이다.
실행순서를 보며 이해해보자.
- transaction B에서 “no_name”을 “i_born”으로 수정 후, commit -> Repeatable Read를 위해 “no_name"이 UNDO에 보관된다.
- transaction A에서 업데이트를 위해 해당 테이블에서 ROW를 검색한다. 하지만, “no_name"은 UNDO에 존재하는 데이터이기 때문에 검색이 되지 않고(19번 SELECT), “i_die"로 수정하는 쿼리(21번 UPDATE)는 반영이 되지 않는다
Repeatable Read는 기존 데이터를 UNDO 영역에 보관 후 수정 전에 시작한 transaction이 조회 시 해당 영역을 보여주는 방식이었다.
하지만, 데이터 UPDATE시 테이블에서 데이터 검색이 필요하고,
이때는 UNDO 영역을 확인하지 않기 때문에 수정하는 과정에서 정합성이 보장되지 않는다.
Phantom Read
Phantom Read는 동일한 query를 2번 실행했을 때 기존에 없던 레코드가 나타나는 현상이다.
이는 Read Committed 이하의 level에서만 발생한다고 생각하지만,
위키피디아에 따르면 WHERE 문을 통한 range-lock 이 올바르게 작동하지 않을 때 발생할 수 있다고 한다.
이해를 위해 타 블로그의 예제를 실행해봤지만, MySQL 8.0 기준에서는 Phantom Read 없이 정상작동했다.
| CREATE TABLE User ( | |
| id INT PRIMARY KEY, | |
| name VARCHAR(100)); | |
| -- transaction A | |
| START TRANSACTION; | |
| SELECT * FROM User; | |
| -- transaction B | |
| START TRANSACTION; | |
| INSERT INTO User (id, name) VALUES (1, "first"); | |
| INSERT INTO User (id, name) VALUES (2, "second"); | |
| INSERT INTO User (id, name) VALUES (3, "third"); | |
| COMMIT; | |
| -- commit transaction B | |
| SELECT * FROM User; | |
| UPDATE User SET name="i_am_spy" WHERE name="first"; | |
| SELECT * FROM User; | |
| COMMIT; | |
| -- commit transaction A |
SERIALIZABLE
Isolation level에서 가장 단순하면서 엄격한 기준. 하나의 transaction이 데이터 조회 시
다른 transaction은 추가/변경/삭제 모두 할 수 없으며, 모든 작업이 순차적으로 이루어져 Phantom Read 도 발생하지 않는다.
하지만, 그만큼 안정성을 위해 성능이 많이 떨어지며 특수한 경우가 아니면 거의 사용되지 않는다.

Reference
Isolation (database systems) — Wikipedia
MySQL :: MySQL 8.0 Reference Manual :: 15.7.2.1 Transaction Isolation Levels
'이론 > 데이터베이스' 카테고리의 다른 글
| Database Index (0) | 2022.04.24 |
|---|
